데이터 모델링 (Data Modeling)
이번 시간부터 약 3회에 걸쳐 데이터 모델링에 대해 다루겠습니다.
데이터 모델링에서 가장 주요하게 다루는 것이 ERD(Entity Relationship Diagram)인데, ERD에 대해서는 다음 시간에 다루기로 하겠습니다.
먼저 이번 시간에는 데이터베이스 시스템을 구축하기 위한 과정에 대해 간략하게 살펴보도록 하겠습니다.
일반적인 시스템 구축 과정을 그림으로 표현한 것입니다. 먼저 그림부터 보시죠.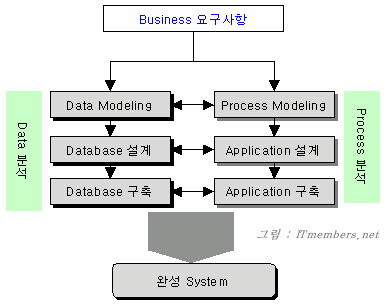
- Business 요구사항
첫눈에 들어오는 것이 바로 Business 요구사항입니다. 바로 업무적으로 필요한 사항들(만약 시스템 개발 업체라면 개발을 의뢰한 회사의 업무 요구사항이 되겠죠)을 듣고, Data와 Process를 나누어서 분석합니다.
왜 Data와 Process를 나누어서 분석하느냐... 눈치 채셨겠지만 우리가 지금 하고자 하는 것이 바로 데이터 모델링을 통해 데이터베이스를 구축하는 것입니다. 데이터베이스의 특징 중의 하나가 바로 데이터와 프로세스의 분리입니다. 분리하는 것이 왜 좋은지는 제2강에서 설명을 했으니 여기서는 생략하겠습니다.
- 데이터 모델링
데이터 분석의 첫번째 단계가 데이터 모델링입니다. 다음 시간에 자세하게 설명하겠지만 Data Modeling이란 데이터베이스 시스템을 구축하기 위해 또는 어떠한 업무를 전산화하기 위해 필요한 정보가 무엇이고, 그 Data들 간의 관계가 어떠한지를 분석하여 그림으로 도식화 하는 과정을 말합니다.
이러한 데이터 모델링이 제대로 되어야지 데이터베이스를 제대로 설계하고 구축할 수 있는 것입니다.
오 른쪽의 프로세스 분석 과정을 보면 데이터 분석 과정과 유사합니다. 즉 실제로는 데이터 분석 과정과 프로세스 분석 과정을 분리해서 생각할 수 없다는 것입니다. 데이터를 분석하는 과정에서 그 데이터에 대한 처리 방법을 염두에 두고 함께 고려하게 됩니다.
자, 그럼 실제 예를 들어 설명을 해보죠.
회사의 종합 관리 프로그램을 만든다고 가정하죠. 그렇다면 우선 사원을 관리하기 위해 사원과 관련된 정보의 집합을 만듭니다. 예를 들어 사원 번호, 이름, 나이 등...
이것을 다음 강좌에서 다룰 일반적인 ERD 작성 규칙에 의거하여 만들면 다음과 같이 표현할 수 있습니다.
EMPLOYEE
(#)number
name
age
데이터 모델링 과정에서 작성하는 것입니다.
- 데이터베이스 설계
그런 다음 데이터베이스 설계 단계에서 실제 테이블을 만듭니다.
아마도 아래와 비슷하게 되겠죠.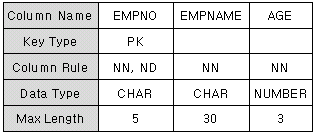
번호를 그냥 NO라고 하면 헤깔리니까 EMPNO라고 하고 마찬가지로 이름과 나이를 EMPNAME으로 정했습니다.
PK는 Primary Key, NN은 No Null, ND는 No Duplicate이라는 뜻입니다.
사원 번호가 기본 키가 되며 빈 값(Null)은 허용되지 않고 중복도 허용하지 않는다는 뜻입니다. Data Type은 문자형(CHAR) 5자리로 구성하고 있습니다.
- 데이터베이스 구축
마지막으로 위의 ERD, 테이블 등을 바탕으로 실제 데이터베이스를 구축해야 합니다.
위의 테이블을 오라클로 구축하려면 다음과 같은 명령을 사용하겠죠.
CREATE TABLE EMPLOYEE
(EMPNO CHAR(05) PK_EMPNO PRIMARY KEY,
EMPNAME CHAR(30) NOT NULL,
AGE NUMBER(03) NOT NULL );
지난 시간에 언급했듯이 Data Modeling이란 데이터베이스 시스템을 구축하기 위해 또는 어떠한 업무를 전산화하기 위해 필요한 정보가 무엇이고, 그 Data들 간의 관계가 어떠한지를 분석하여 그림으로 도식화 하는 과정을 말합니다.
그 중 가장 대표적인 방법이 바로 ERD입니다.
ERD는 Entity Reationship Diagram의 약어입니다.
그럼 먼저 Entity가 무엇인지 알아야겠네요.
- Entity Relationship
entity는 우리말로 '실체', '존재'라는 뜻입니다. 굉장히 모호하고 추상적입니다. 맞습니다. entity는 추상적으로 쓰여서 여러 분야에서 다른 의미로 사용됩니다. 그러나 우리가 지금 학습하고 있는 데이터 모델링에서 entity는 "분류될 수 있고, 다른 entity들에 대해 정해진 관계를 갖는 데이터 단위"라는 뜻입니다.
더 헤깔린다구요?
예를 들어 설명하죠.
만약 어떤 회사에서 관리 프로그램을 만든다고 할 때, 데이터베이스에는 어떤 정보가 저장되어야 할까요?
회사 내의 부서, 사원 등에 대한 정보가 있어야겠죠? 여기서 부서, 사원 등에 해당되는 개념이 바로 entity입니다. 한마디로 "업무에서 필요로하는 관련된 데이터의 집합"으로 규정할 수 있죠.
relationship 은 entity들 간의 관계를 말합니다. 나중에 자세히 설명하겠지만, 부서와 사원의 관계가 "모든 사원은 반드시 하나 이상의 부서에 속해야한다"는 관계로 성립될 수 있습니다. 이러한 entity들 간의 상호 관계를 relationship이라고 합니다.
따라서 결론,
Entity Relationship Diagram은 "entity들 간의 상호 관계를 그림으로 도식화한 것"이라고 정의하면 되겠죠.
- Attributes
그러나 entity만 가지고는 정보를 표현하기에 부적합합니다. 조금 전 부서, 사원 등이 entity에 해당된다고 했는데 각각의 사원은 사원번호, 이름, 나이, 연봉 등의 값을 가지고 있습니다. 부서는 부서의 코드와 부서 이름 등의 하위 값을 가질 수 있죠. 이렇게 entity가 가지고 있는 보다 구체적인 데이터를 attributes라고 합니다.
자, 이제 위에서 언급한 entity와 attributes 그리고 relationship을 그림으로 표시하면 다음과 같습니다.
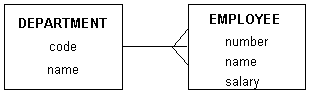
- DEPARTMENT entity는 code, name과 같은 attributes로 구성되어 있고,
- EMPLOYEE entity는 number, name, salary와 같은 attributes로 구성되어 있되,
- 하나의 DEPARTMENT는 여러 개의 EMPLOYEE를 가질 수 있다는 뜻입니다.
이번 시간에는 ERD를 그릴 때 약속된 표기 방식에 대해 알아봅니다. entity와 attribute, relation을 어떻게 표현하는지 정확하게 이해하고 넘어가시길 바랍니다.
- Entity
entity는 사각형 안에 영문 대문자로 표시합니다.
entity의 이름은 중복되지 않아야 하며(unique) 단수로 표기합니다.
- Attribute
마찬가지로 단수로 표기하되 소문자로 표시합니다.
attribute는 중복되면 안되는 것(unique), 꼭 있어야 하는 것(mandatory), 있어도 되고 없어도 되는 것(optional) 등이 있습니다.
다음 그림을 보세요.
위에서 #* 표시는 unique, *표시는 mandatory, o표시는 optional을 나타냅니다.
- Relationship
다음은 relationship을 나타낼 수 있는 몇 가지 방법들입니다.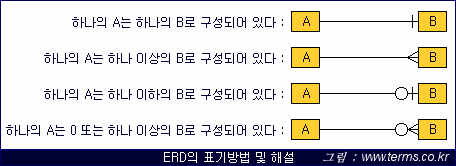
보다 구체적으로 하나씩 살펴보죠.
- Mandatory
mandatory는 '강제', '의무'라는 뜻을 가지고 있습니다.
DEPARTMENT는 반드시 하나 이상의 EMPLOYEE를 가져야한다는 뜻입니다.
- Optional

DEPARTMENT는 EMPLOYEE를 가질 수도 있고 그렇지 않을 수도 있다는 뜻입니다. 원 표시가 바로 Optional이란 의미입니다.
- 1:M Relationship(일대다 관계)
위에서 예로 든 "하나의 entity는 하나 이상의 다른 entity를 가질 수 있는 관계입니다. 가장 일반적인 관계입니다.
DEPARTMENT entity 박스에 세로로 1자를 그어놓았죠.. 바로 1대다(多) 관계를 말합니다.
이럴 경우 DEPARTMENT는 EMPLOYEE를 여러개 가지거나 하나도 가지지 않아도 되지만, EMPLOYEE는 반드시 하나의 DEPARTMENT를 가져야한다는 뜻이 됩니다.
- Mandatory
그외에 1:1, 다:다 관계가 있는데, 보다 자세한 설명이 필요하므로 다음 시간에 설명드리도록 하겠습니다. 왜냐하면 일대일 또는 다대다 관계가 성립될 경우 가급적 일대다 관계로 다시 변경해 줄 필요가 있는데 그 과정에서 설명이 조금 더 필요하기 때문입니다.
지난 시간에 일대다 관계가 일반적이라는 말을 했습니다. 그런데 업무 요구 분석을 하다가 보면 일대일 또는 다대다 관계가 성립될 때가 있습니다.
이럴 땐 어떻게 해야할까요?
실제로 일대일 또는 다대다 관계라 할지라도 효율적인 데이터베이스 프로세싱을 위해서는 일대다 관계로 변형하는 것이 좋습니다.
먼저 일대일(1:1) 관계가 성립될 경우입니다.
그림으로는 아래와 같이 나타냅니다. 
택시 기사는 반드시 면허증을 가져야 합니다. 그리고 그 면허증은 반드시 한 사람에게만 적용됩니다. 택시 기사 한 사람이 여러 개의 면허증을 가지거나 하나의 면허증으로 여러 택시 기사가 나누어 가질 수는 없다는 뜻입니다.
이럴 경우 의미적으로는 일대일 관계가 맞다고 하더라도 효율적인 데이터베이스 처리를 위하여 두 개의 entity를 합쳐 하나로 통합하는 것이 좋습니다.
다음 그림과 같이 말이죠.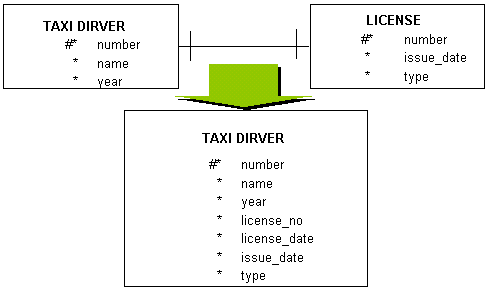
이제 TAXI DRIVER entity는 기존의 LICENSE entity의 attribute까지 모두 포함한 하나의 entity가 되었습니다.
다대다(M:N)의 관계를 살펴봅시다.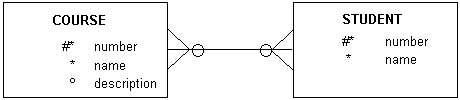
위 그림에서 여러 개의 강좌와 여러 학생들이 다대다 관계로 성립되어 있습니다. 학생은 여러 개의 강좌를 동시에 수강해도 되니까 말입니다.
이렇게 의미적으로 다대다 관계가 성립된다고 하더라도 그대로 둘 경우 상당히 관리하기가 복잡해집니다.
이럴 때는 따로 관리할 수 있는 정보를 별도로 떼어내어 하나의 entity를 구성한 다음 이 entity를 중심으로 1:다 관계를 새로 정립하는 것이 좋습니다.
아래 그림을 보죠.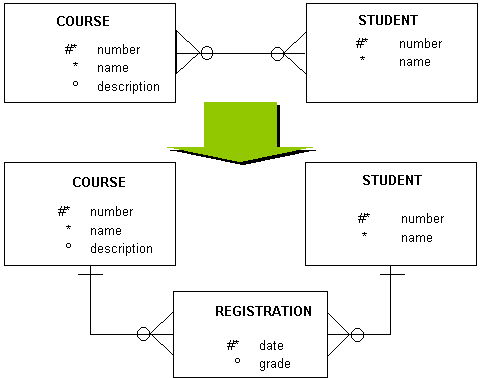
이러한 작업이 위의 예처럼 그리 쉽게 해결되지 않을 때가 많습니다. 그래도 여러 방법을 구사하여 가급적 일대다 관계로 풀어내어야 데이터베이스의 처리가 한결 수월해집니다.
http://aruesoft.tistory.com/47
'정보과학 IT' 카테고리의 다른 글
| PLC 란 무엇인가? (0) | 2018.02.22 |
|---|---|
| 논리적 모델링과 물리적 모델링 (0) | 2014.03.24 |
| EAI (Enterprise Application Integration) : 기업 애플리케이션 통합 (0) | 2014.01.22 |
| ISP (Information Strategy Plan) : 정보전략계획 (0) | 2014.01.21 |
| 인트라넷 (0) | 2014.01.17 |